キーボード #2 Advent Calendar 2023の19日目の記事です。18日目はPekasoさんの「自作キーボードのケースをアクリル板でいい感じに作る2023」でした。どれも上手いアイデアでとても参考になるし、仕上がりがきれいなのでさすがですね。
さて、この記事で話題にするのはタイピングデータです。 自分のデータを分析してみたら、全く予想していなかった特徴があることが分かりました。 ここでは私のタイピングデータの分析を紹介し、その特徴を考察します。
はじめに
キーボードの配列の最適化問題はおそらくまだ誰も明確な答えを持っていない興味深い課題です。 配列の良し悪しは様々な基準で評価されていますが、 私は個人のタイピングの癖や特徴を把握する必要があると考えています。 そんなわけで自分のタイピングデータを収集するために、自作したWindowsアプリ(Keyboard Typing Analyzer)を作ってデータを集めています。
使用しているキーボードはrow staggeredのQWERTY配列で、
主なサンプルデータはブログや日記などを日本語(ローマ字入力)で書いているときのタイピングと、英語のタイピングテストです。
Keyboard Typing Analyzerでは入力したキーと時間を記録しており、例えば連続した2入力(以降2連接と呼ぶことにします)にかかる時間や頻度などを知ることができます。日本語の文章をタイプしているときのデータをグラフにしてみると、全く予想していなかった分布が現れました。
日本語入力の時の不思議な分布?
下図の左は2連接にかかった平均時間(横軸)とその頻度(縦軸)の相関です。各点は「su」や「ta」などの各組み合わせを表しています。例えば一番頻度の高い点(132.4, 1646)は「nn」です。 ここでは頻度が極めて少ないものはミスタイプとみなして除いてあります。
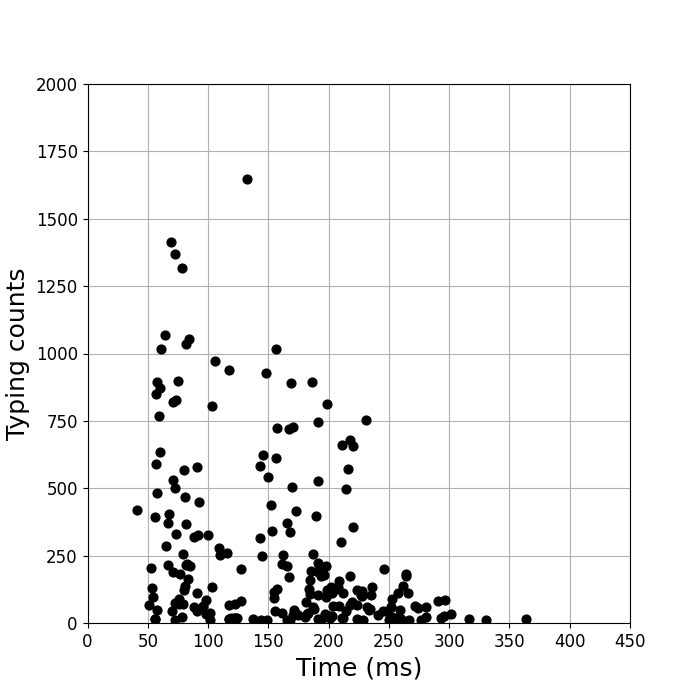

この図を見ると弱い相関がみられます。
頻度が高い組み合わせは、それを最適化するように自分が適応したためか、入力時間が短い傾向があります。
頻度が高い組み合わせで入力時間が250 msを越えるものはありません。
予想外で驚いたのは入力の速いグループと遅いグループの2つに分離しているように見えることです。これは右図の1次元ヒストグラムをみると、よりはっきりします。 2つのピークの間隔はわずか0.1秒程度しかありませんが、これほどはっきりと分かれているのは何か理由があるに違いありません。 これを明らかにするため、あれこれ調べてみました。
英語のタイピングテストのデータ
英語のタイピングテストだとどうなるのか、という疑問がまず浮かびました。 見てみたのが下の図です。
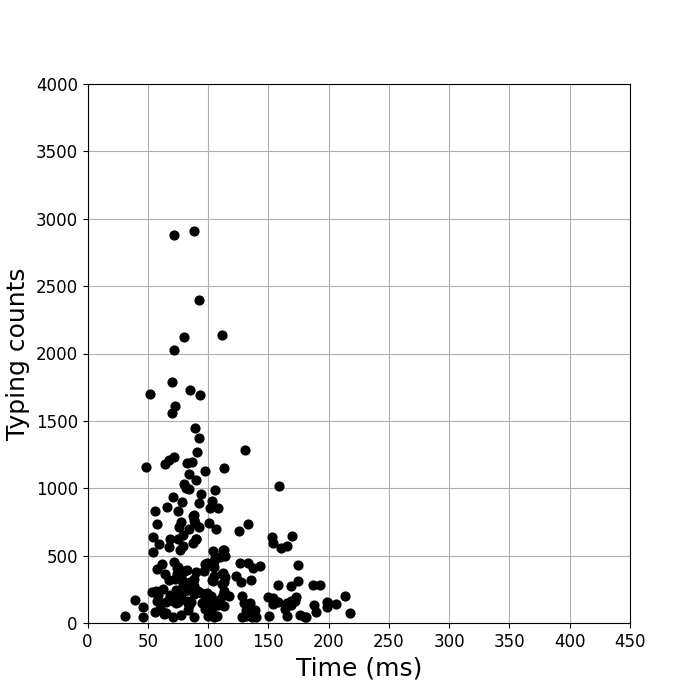

頻度が高いものは入力時間が短い傾向があるというのは、日本語入力のデータと同じです。 しかし入力時間分布が2つのグループに分かれている、ということはありません。
2連接の入力パターンによる分類
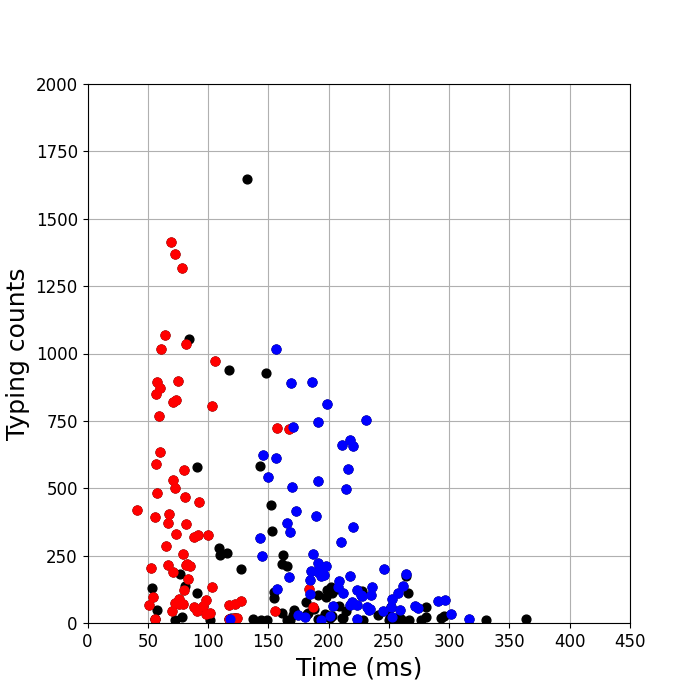
さらに調べてみると、どうも子音+母音(下図赤)という組み合わせの場合は入力が速く、母音+子音(下図青)の組み合わせは遅いグループとなっていることがわかりました。

英語のタイピングテストのデータで同じことを見てみると、子音+母音、母音+子音で入力時間の分布に大きな差はありません(下図)。
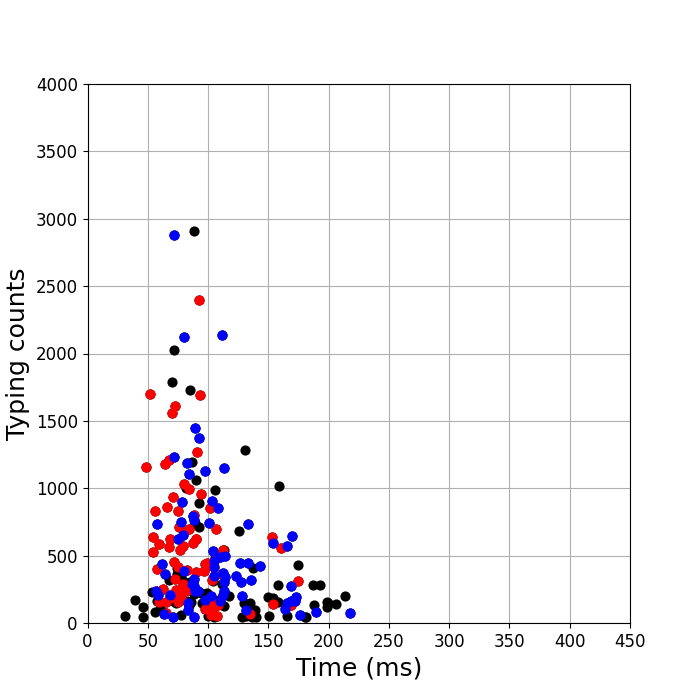

ちなみにこれらのサンプルデータは、書く内容を考えながらタイプしているのと、画面に表示されている文字をそのままタイプしている、という違いがあります。 そこで統計量は少ないですが、日本語のタイピングテストの場合も見てみたのが下の図です。
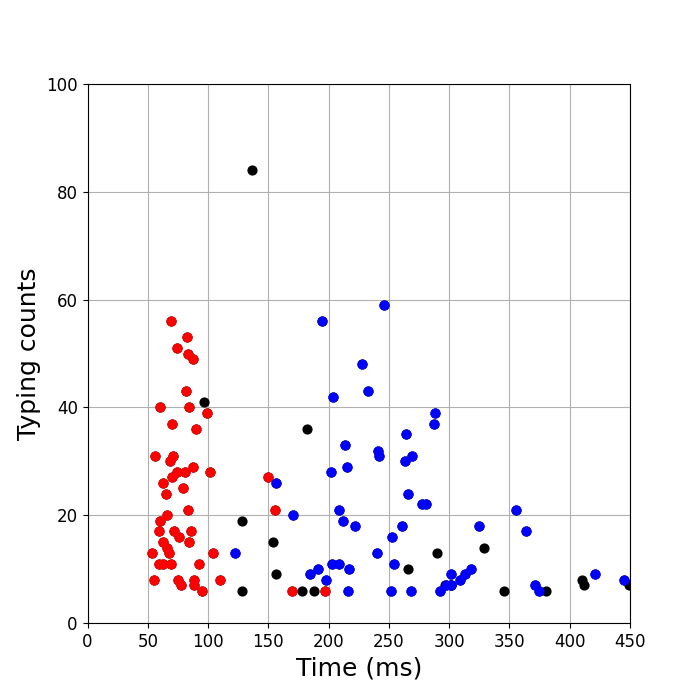

2つのグループに分かれています。 これは日本語の文章を入力しているときと一緒です。 タイピングテストかどうかではなく、日本語と英語で違うようです。
この違いはなぜなのか?
上の入力時間分布の違いは、日本語と英語で入力単位が異なるからと解釈できる気がします。
ここで入力単位は一気に連続して入力する塊とします。
日本語ローマ字入力の場合、ほとんどの文字は子音+母音の組み合わせでひらがな1文字を形成し、多くの場合は子音と母音が交互に現れます(ちゃんと調べていないのでどれくらいの割合かは不明)。
入力の単位がひらがな1文字となっていれば、子音、母音、少し時間が空いて、子音、母音と打鍵される場合が多くなり、母音+子音のパターンの入力時間が遅くなりそうです。
あるいは入力単位が単語や文節ということも考えられます。
日本語では漢字変換のためにスペースキーを押します。
私は比較的短い文節で変換しますが、本分析では"a k"のようにaとkの間にスペースが入力された場合は2連接と判定していません。もし文節の入力中は母音・子音関係なく同じリズムで打鍵できているとすると、上の図のように2つに分離するような顕著な違いは現れないでしょう。
自分としてはスムーズに文節を打鍵しているつもりですが、実際にはひらがな1文字が入力単位になっているようです。
これに対して英語のタイピングテストでは、入力単位が単語になっている気がします。
実際にタイピングしている感覚としては1単語は1入力単位、もしくは2入力単位(例えばinc-rease)がほとんどだと思います。
以上のことは自分が感じているタイピングのリズムとリンクしていると思います。英語をタイピングしていると単語によっては3つ以上の入力を素早く打てるコンボがあり、心地良さを感じることができます。これにより1単語をシームレスに打鍵していると感じることがよくあります。
一方、日本語を打鍵しているときはコンボを感じることがありません。入力単位がひらがな1文字となっていれば、3入力以上がシームレスに打鍵できない、と説明がつきます。そういう点では母音を片手側に集めたキー配列を使えば左右交互に打鍵するリズムが生まれ、体感が良いのかもしれません。あるいはかな入力にすれば、英語打鍵時にあるような心地よい入力コンボを日本語入力時にも得やすくなるのかもしれません。
2連接の列(Column)の組み合わせごとの入力時間
配列の最適化のためには、連続打鍵の指の組み合わせが重要であると考えています。 そこで指に対応している各列(Column)の組み合わせごとの入力時間、頻度を見てみました。 qaz列を0、wsx列を1、…、pを9のように定義し、2連接の最初の入力を横軸に、2番目の入力を縦軸にとって入力時間の平均と頻度を示したのが下の図です。 白い色になっているのはz軸がゼロに対応しています。
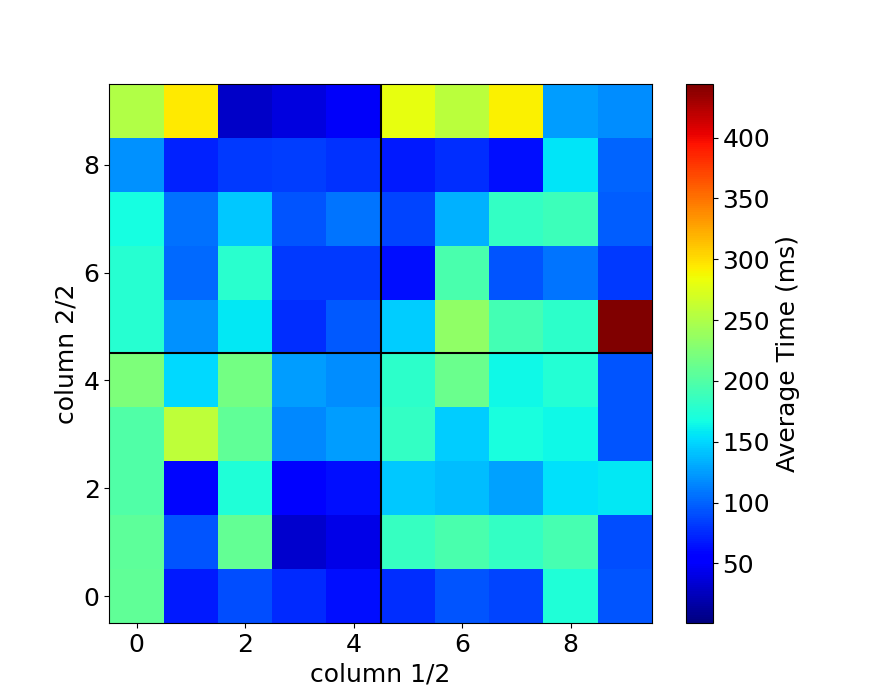
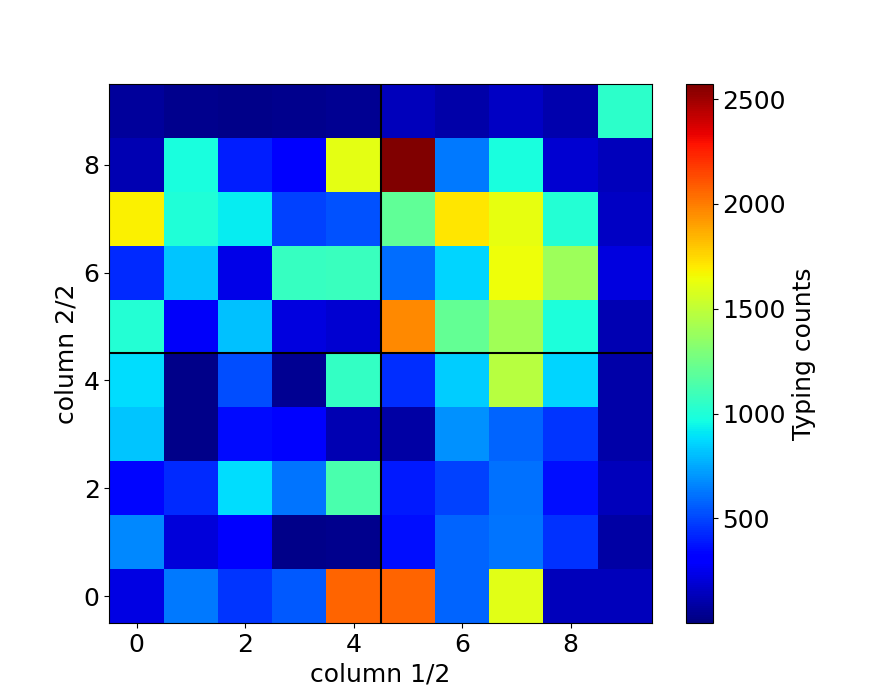
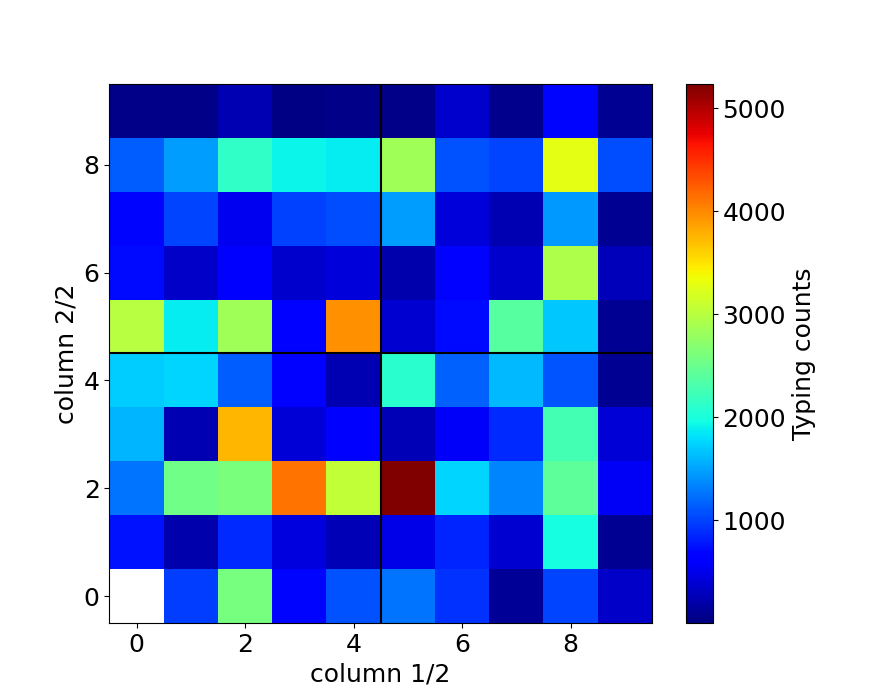
これを見ると以下のことに気づきます。
- 日本語入力の場合、右手右手の入力回数(22,163回)は左手左手(12,755回)よりも多い
- 英語タイピングテストの場合、qaz列を連続入力することが無い
- 英語のタイピングテスト時は同じ列(=同じ指)の連続入力は明らかに他よりも遅い
2.に関しては、タイピングテストが選択している単語によるものかもしれません。
実際の英文ではpuzzleなどqaz列が連続するものが現れる可能性がありますが、やはり頻度は少ない気がします。
3.の同じ指の連続打鍵が遅い、というのは自分の体感と一致します。
ただし例外もあります。(第5列, 第6列)の入力(yhn列, ujm列)は入力時間が短くなっています。
これは私がnumberなどを打鍵する際、nを右人差し指、uを右中指、のようにnとuに別の指を使って速く打鍵しているからです。
快適なタイピングを求める際、配列や運指を工夫することにより、どれだけ同じ指の連続打鍵を減らせるかが1つのポイントになるでしょう。
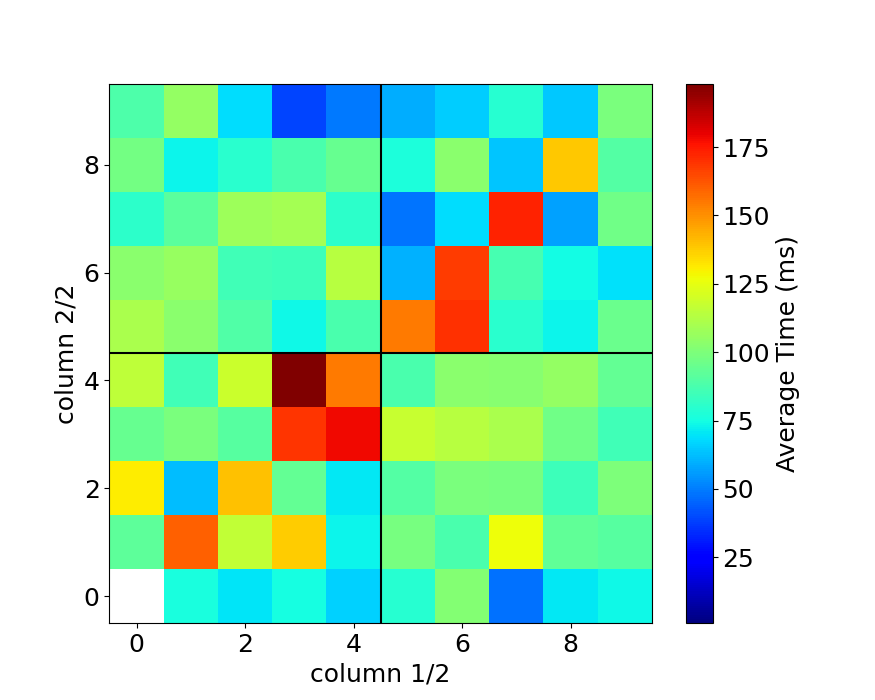
2連接の各キーの組み合わせの入力時間
最後に2連接の各キーの組み合わせについての入力時間を示しておきます。 上と同様に横軸が1番目の入力、縦軸が2番目の入力になります。
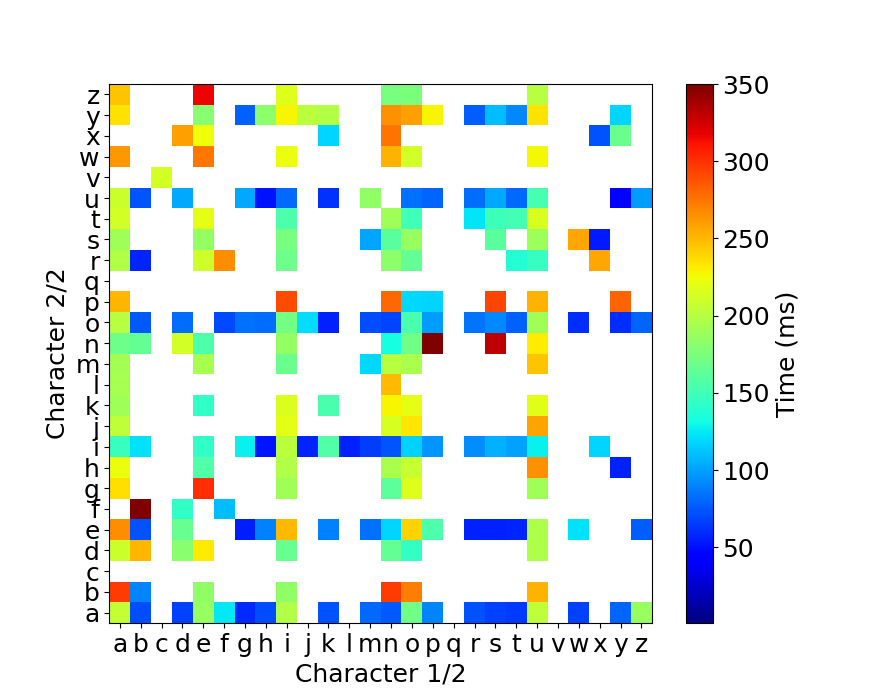
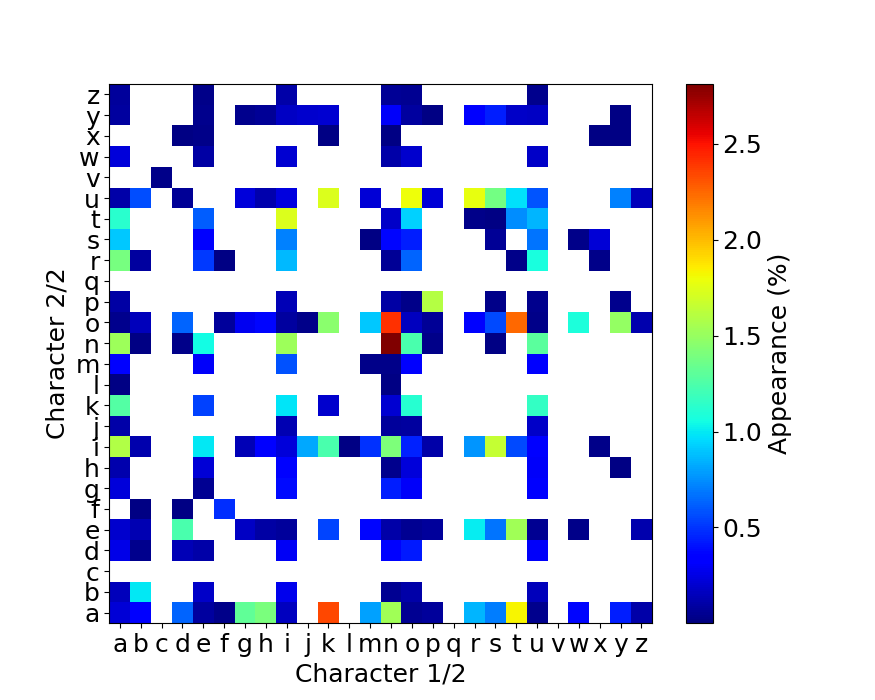

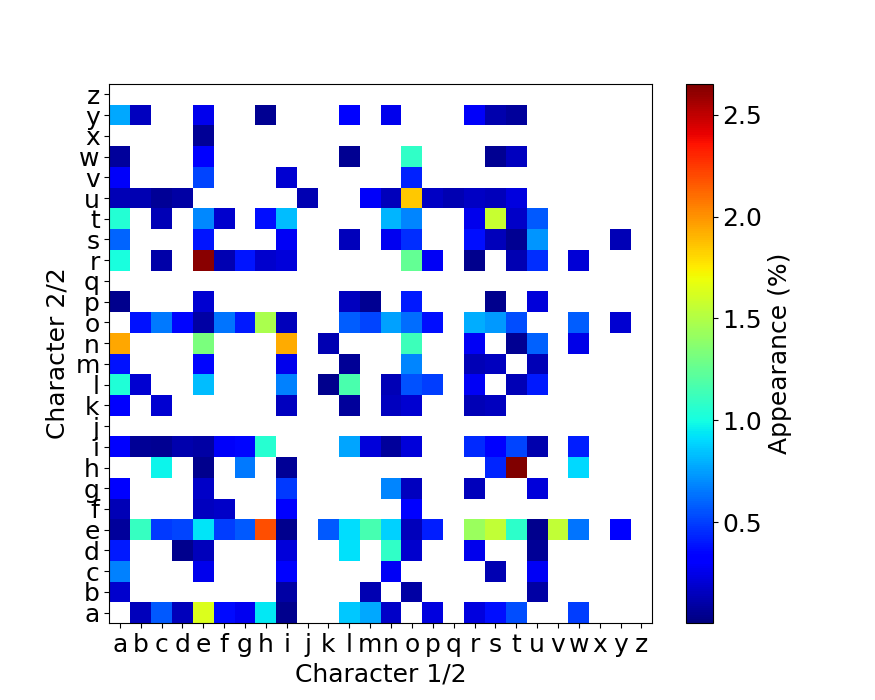
ここまで細分化すると、組み合わせが多すぎて傾向はよくわからないですね…。
よく見ると、cvなどの日本語入力ではありそうもないパターンがあるので、ミスタイプを排除しきれていないようです。
ミスタイプの判定はさらに工夫する余地があります。
これらの図を見ると、データが存在している組み合わせは結構限られています。
アルファベットの組み合わせは26 x 26 = 676通りあるわけですが、実際に使用している(上の図の白ではないマスの数)のは、日本語だと224通り、英語タイピングテストだと225通りしかありません。
入力している文字が偏っている可能性もありますが、配列の最適化を2連接のデータで考える場合、676通り全ての組み合わせを考える必要はなく、せいぜい230通りくらいを最適化すれば十分なようです。
さらに自分のタイピングの癖をある程度知ることができます。 例えば「ぃ」の打鍵の仕方はxiやliなどがありますが、私は「xi」としているようです。 「ぃ」はたいてい(必ず?)子音を前に伴うので、「thi」などのように打鍵することでもっと速くタイプできるはず。
あとがき
自分のタイピングデータを分析してみましたが、言語によって明らかに様子が違います。
予想してはいたものの、ここまで大きく異なるのは意外でした。
言語によって最適な配列が変わるはずなので、レイヤーごとに配列を変えて、入力言語でレイヤーを切り替えるといいのかもしれません。
(かな入力の人は英字入力の時にはそうしている?)
これだけ入力時間分布が異なるということは脳の使い方も全く異なっているんだと思います。
でも日本語の文章でも日本語のタイピングテストでも同じように入力時間分布が2つに分離していました。
文章書くときとタイピングテストは全然違う脳の使い方をしている気がするんですけどね。
これは自分の日本語ローマ字入力のタイピングがまだまだ未熟ということなのか、あるいはキー配列が良くないのか…。
明日の記事は五月雨さんです。
このキーボードは自作オリジナル65%キーボードunity69で書きました。